株式会社FRONTEO
- HOME
- 株式会社FRONTEO
- 製品・サービス詳細
- 自社開発のAI「KIBIT」
自社開発のAI「KIBIT」の提供を通じた、社会課題と向き合う各分野の専門家の判断支援
会社カテゴリー:ITソリューション
主サービス提供地域:
製品・サービス詳細
自社開発のAI「KIBIT」
サービスカテゴリー:研究・開発、再生医療、データ処理、臨床、製造

FRONTEOの自社開発AI「KIBIT」は、論文や医療データ(カルテや問診の会話など)のテキストデータを解析し、創薬研究者の活動や医療従事者の診断を支援します。AIの強みである膨大なデータの網羅的な解析はもちろん、発見を導くことに特化したアルゴリズムによって、人が文章を読むだけでは気づきにくい関連性を見つけ出すのが最大の特長です。この独自アルゴリズムは、人によるバイアスやAIで起こりやすいハルシネーションも回避することが可能です。
|
新規の関連性を予測、発見 非連続的発見という新しいアプローチによって、“未報告”、つまり論文に記載されていない新たな関連性を見つけ出します。
|
仮説への着想を得るためのマップ化 AIの解析結果を可視化して情報同士の作用や関連を見渡せるようビジュアル化し、医療現場での判断や研究での仮説の着想をアシストします。
|
専門分野を横断して 異なる分野それぞれの用語の意味合いや使われ方、つまり特性を失わないまま解析ができる独自アルゴリズムで、領域をまたいで有益な情報を見つけ出せます。
|
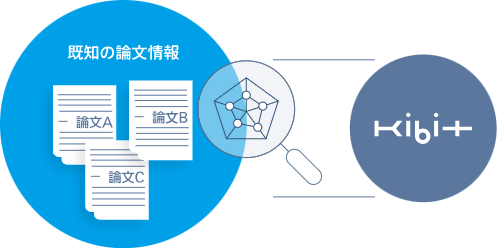



自社開発AI「KIBIT」が
社会解決の解決に挑む専門家の高度な判断を支援
FRONTEOの自社開発AIエンジン「KIBIT(キビット)」
「KIBIT(キビット)」は膨大なデータから最適な情報の発見を導くAI
「KIBIT(キビット)」は、FRONTEOが自社開発し、改良を続けるAI(人工知能)です。自然言語処理とネットワーク解析に強みをもち、膨大なデータの中から発見を導くことで、課題解決に取り組む専門家に全く新しい視点や気づきを提供するAIです。
|
テキストを解析する言語系AI 「KIBIT」は、文章から人の暗黙知や感覚を読み取って人の判断や情報の探し方を再現することで、人に代わって大量のデータを処理します。 |
非構造なデータからの発見・検索 大量のテキストデータから成る書類やメール、論文のデータは、そのままでは数値データのように解析することが困難です。 |
|
独自のベクトル化とアルゴリズム KIBITでは、ChatGPTなど生成AIで主流のTransformerとはまた別の、独自アルゴリズムを開発して用いています。 |
データを直感的にビジュアライズ 情報の全体像や特徴、要素どうしの関連性などを直観的につかむため、マップ化による"可視化"も重視しています。 |



「KIBIT」は数学的アプローチでシンプルな構造のAIエンジン
FRONTEOのAIは、「世界で起こるすべての現象は数式で表現できる」という考えのもと、数学的アプローチでシンプルな構造のAIエンジンを開発しています。人間の心の「機微」と情報量の単位である「bit」を組み合わせ、「人間の機微を学習できるAI」として「KIBIT(キビット)」と名づけました。
自然言語処理とネットワーク解析の強みを生かして、専門家の高度な判断を支援します。

AI「KIBIT」と生成AIの違い
生成AIとは、学習したパターンを元に画像や文章など元データとは別のコンテンツを生成するAIのことで、中でも言語系の生成AIとしてChatGPTやGeminiなどが有名です。大規模言語モデル(LLM)は生成AIの一種で、膨大な量のテキストデータを学習させた深層学習モデルのことです。
一方でFRONTEOのAI「KIBIT」は、高い専門性を持つ専門家の判断・暗黙知をアルゴリズムで再現し、膨大な情報から必要な情報を探し出し、発見を導くことに長けています。
|
KIBIT
ノートPCレベルで動作できる軽さ ハルシネーションのリスクがない |
言語系の生成AI・大規模言語モデル(LLM)
次の単語の予測に最適化したモデル 大規模な計算資源を必要とする 出力結果のハルシネーションに注意 |


ビジネスの目的ごとに最適化したAI「KIBIT」の独自アルゴリズム
「KIBIT(キビット)」は、FRONTEOが自社開発しているAI(人工知能)で、自然言語処理とネットワーク解析に強みをもち、膨大なデータの中から発見を導くことに特化しています。
KIBITがもつ3つの機能と、その機能を支えるアルゴリズムの特長をご紹介します。
「KIBIT」の機能①:検索・分類
・文章や単語の"意味合い"で検索や分類ができる
・多義語や表記揺れも高精度で認識して検索できる
単純なキーワード一致だけでなく、単語や文章全体の意味合いをAIが見抜けるので、文書・論文の検索やコメントの分類を最適に行えます。これは、独自のベクトル化技術によるアルゴリズムで言葉どうしの数学的な近さ、つまり類似性を高い精度で見出せるためです。文章への単語の寄与度合いの計算や元の文章の特性を保った統合的な探索など、複数の独自手法も組み合わせて解析します。
「KIBIT」の機能②:発見・抽出
・大量のメール・文書から証拠や予兆を見つけ出せる
・AIが文脈を読んでいるかのごとく文章を解析できる
弁護士や監査担当者が文書から証拠を見つけ出す感覚や、文章全体がもつ雰囲気などを、独自のアルゴリズムで数値・数式化できます。これにより、AIが大量の文章を人の代わりに監査・レビューできます。テキスト以外の情報の特徴量への活用、単語への重み付けの自動最適化などの工夫のほか、過学習を抑える独自手法もアルゴリズム内に組み込むことで、発見・抽出の精度を高めています。
KIBIT」の機能③:ネットワーク解析
・企業間取引のチョークポイントや隠れた支配を発見できる
・ネットワーク内の影響力伝搬やつながりの強さを可視化できる
オープンソースや企業の独自データを解析することで複雑な情報ネットワークを描き出し、物の流れや影響力の伝搬度合いをAIで可視化して全体像のスピーディーな把握を可能にします。経済安全保障に欠かせないサプライチェーン中の企業間のつながりや株式保有関係、共著関係に基づく研究者/研究機関どうしのつながりといった種々のネットワークを解析するための技術や独自指標を開発しています。
AI「KIBIT」の活用シーン
FRONTEOのAI「KIBIT」は、創薬研究者や医師、弁護士や監査人など各分野の専門家の活動を支援し、社会課題の解決を加速させます。
| 創薬の標的探索 | 論文探索・論文データ解析 | 米国訴訟(eディスカバリ)支援 | 不正調査・メール監査 |
| お客様の声分析 | 書類など非構造化データの検索 | サプライチェーン解析 | 研究者ネットワーク解析 |
AI「KIBIT」独自の特長
膨大なデータから発見を導くことに特化しているFRONTEOの自社開発AIの「KIBIT(キビット)」は、LLM(大規模言語モデル)やLLMベースのChatGPTをはじめとする生成AIとは一線を画する、独自の特長をもっています。
AI「KIBIT」独自の4つの特長
ポイント1
独自技術のベクトル化
KIBITでは、自然言語(人の言葉)をAIで解析するために欠かせない「ベクトル化」、つまり言葉の数値へ置き換えにおいて、自社独自の技術を開発していることが大きな特長の一つです。
これは専門的に言えば「語の共起関係に加えて、単語や文の関連性を捉える」手法で、この独自手法で行ったベクトル化は、生成AIなどで広く使われるTransformerよりも結果が良かったことが裏付けられています*。
*〈Yamada et al.(2020)〉
ポイント2
多くの特許からなる独自アルゴリズム
文書(自然言語)やネットワークの高度な解析を行うために、生成AIで広く用いられるTransformer* とは異なる独自アルゴリズムを開発しています。文脈を捉えるための単語パターンの解析や、語への適切な重み付け、そして特徴量の最適化など、アルゴリズムやデータの解析・可視化手法などに関わる70以上の自社特許を駆使して、高い精度で最適な解析結果を出力できます。
さらにAIを搭載するソフトウェアまで自社開発で提供しているので、企業のデータや課題に合わせたカスタマイズや追加開発を行いながら実装することができます。
* Transformer(トランスフォーマー): ディープラーニングのモデルの一つで、2017年に発表された自然言語処理の手法。
ポイント3
インサイトと発見を導くマップ化技術
KIBITでデータを解析した結果は、ただ出力するだけでなく、「マップ化」というアウトプットをすることで、専門家の思考や判断を助け、さらなる発想を促します。
適切に処理したデータ* を平面上にプロットして人が視覚的に認識できる「2次元マップ」とすることで、色や散らばり具合などの表現を通して情報どうしの作用や関連まで見渡すことができるため、ただの解析では見逃してしまう予想外の情報をも発見する「セレンディピティ」にもつながります。
* 次元圧縮または次元削減。元となる膨大なテキスト情報を、多くの数値の組である特徴ベクトルに置き換え、そのベクトルの関係性を保持しながらデータを2次元の緯度経度情報まで圧縮する。
ポイント4
省エネのGreen Micro AI
各方面からの期待が高まる生成AIは、実は大量の電力を消費すること、それに伴うCO2の排出や水の消費の観点などが指摘されています。
KIBITのアルゴリズムはLLM(大規模言語モデル)とは異なり、シンプルで、専門家の優れた判断や暗黙知を再現します。少量の教師データでも使用可能でCPUレベルで高速・高精度の解析をするKIBITを、私たちはGreen micro AIと呼んでいます。